Sonification for Explainability in Large Language Models

The work below was conducted as part of a semester-long project for the Advanced Topics in Human/Machine Intelligence (CSCE 6290) course at the University of North Texas during the Spring 2025 semester. Most of the descriptions included here were written for a term paper summarizing the results of this project, which can be downloaded here.
Introduction
The increasing ubiquity of artificial intelligence (AI) tools in modern life highlights a growing need for AI systems that are understandable for ordinary people. However, public opinion on the ubiquity of AI tools differs relative to one’s level of expertise in the technical capabilities and limitations of AI [6], including feelings of optimism and anxiety about AI. Non-experts, for example, are more likely to believe that AI will cause harm to humanity in the future [6:49].
AI explainability, or explainable AI, generally describes the ease at which humans can comprehend how an AI agent generates predictions [1]. Sonification, which can be understood as the transformation of data into sound [2:274], is posited to be one way of enhancing AI explainability [8].
This project examines the ability of existing large language models (LLMs) to generate and comprehend a mapping of words encoded as audio frequencies for use in sonification. The results indicate that LLM outputs can be used for sonification, but models struggle to translate sentences using encoded languages without exposure to the encoded language during training. Finally, a hybrid ensemble architecture is proposed as a means for capturing and generating audio from LLM outputs.
Data preprocessing
Several LLM models, including nanoGPT [5] and DistilGPT2 [3], were tested for their ability to receive encoded prompts, interpret the prompts as language, and generate encoded responses that can be recreated as audio. ChatGPT was also tested, but the results are difficult to reproduce consistently and are excluded here.
Since LLMs are typically designed to interact with and generate textual data, sonification requires formatting audio-based model inputs such that they can be decoded as text, and formatting model outputs such that they can be used to create digital audio. Additional tools, such as software synthesizers, can then be used to produce sound.
Character mapping
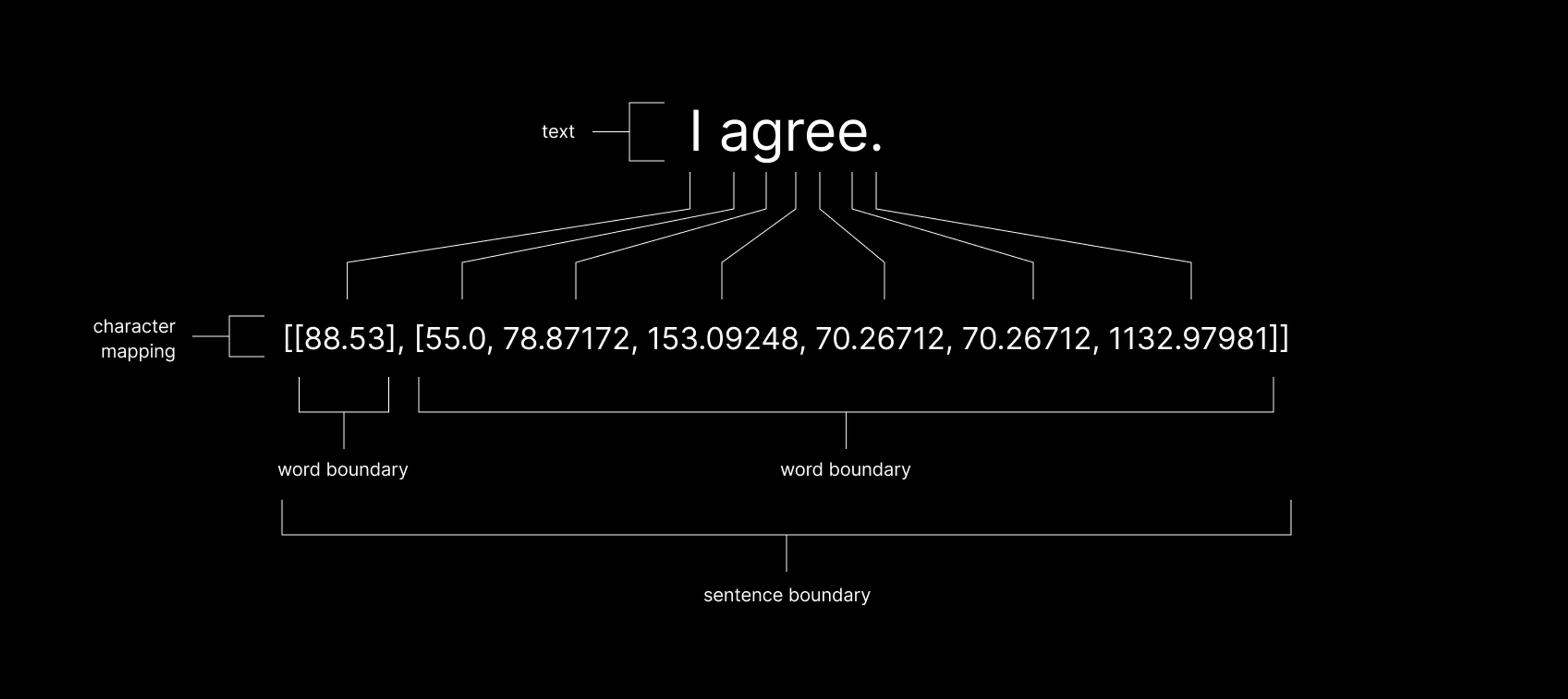
The first step in this project involved creating a character mapping suitable for converting text to audio frequencies, generating sonifications of LLM outputs, and translating sonifications back into text. The character mapping was created by encoding every letter, number, and punctuation mark in the English language as a set of unique numbers representing audio frequencies that fall within the range of human hearing (i.e., 20– 20,000 Hz). Words are formatted as nested lists of floating-point values. Word boundaries are contained within single brackets and sentence boundaries are contained within double brackets (Figure 1).
Simulating LLM conversations using a LSTM translator
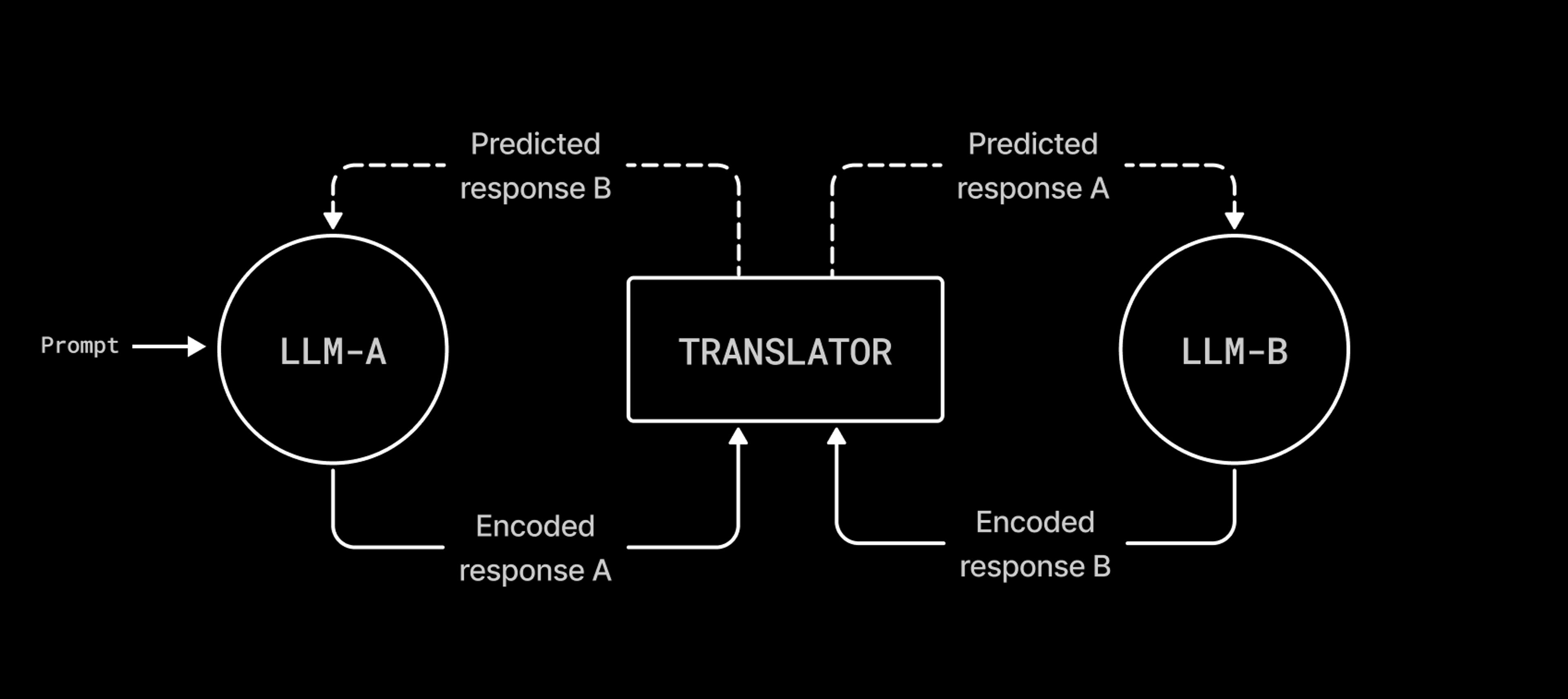
An initial test of the sonification pipeline involved simulated conversation loops between two models, LLM-A and LLM-B, in which plain-text sentences are encoded as audio frequencies, translated back into text, and used as prompts. The simulation was achieved by training a long short-term memory (LSTM) model to predict textual characters associated with audio frequencies, then using the LSTM model as a translator between two DistilGPT2 models fine-tuned on the openwebtext dataset. A diagram of the simulation flow is shown in in Figure 2 above.
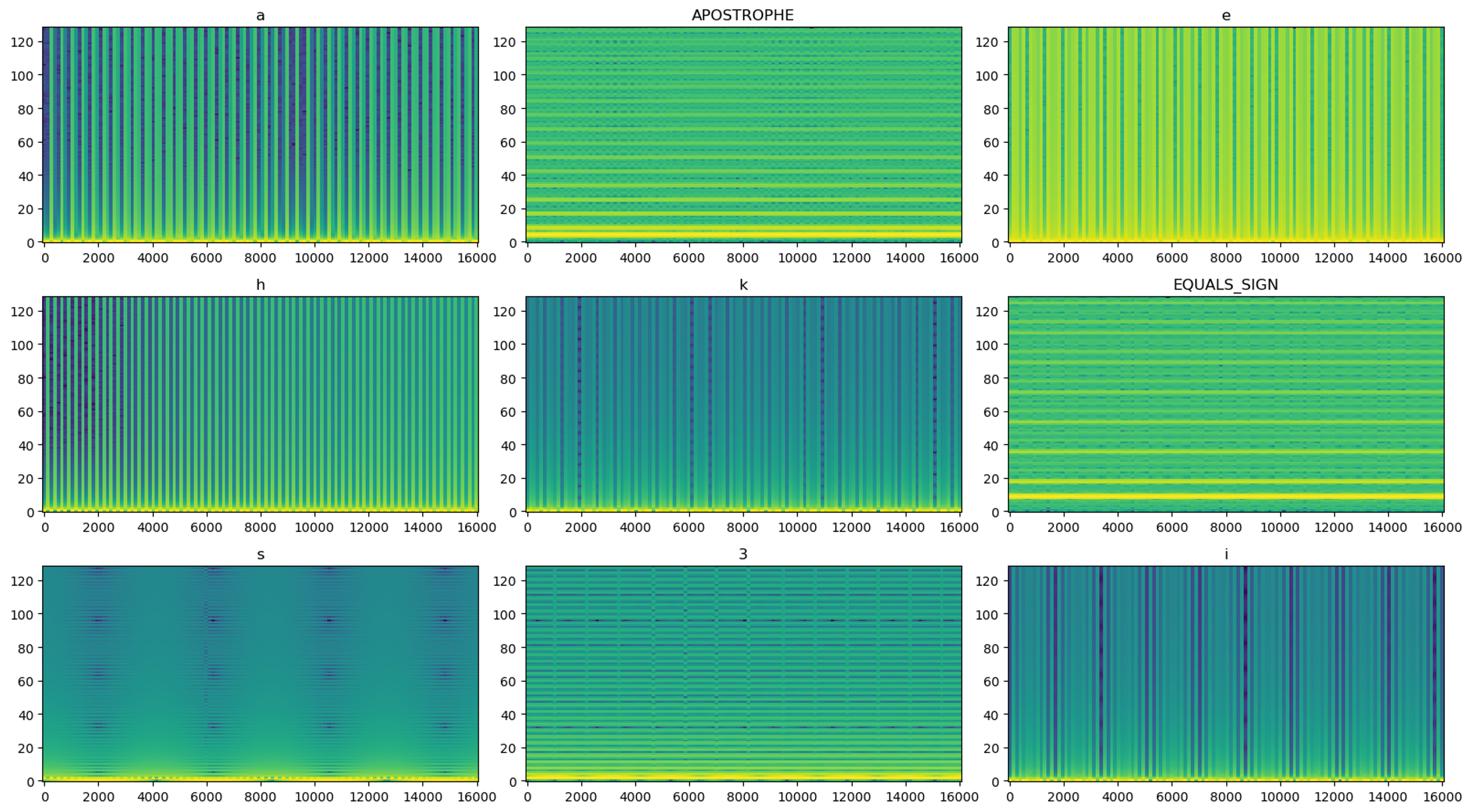
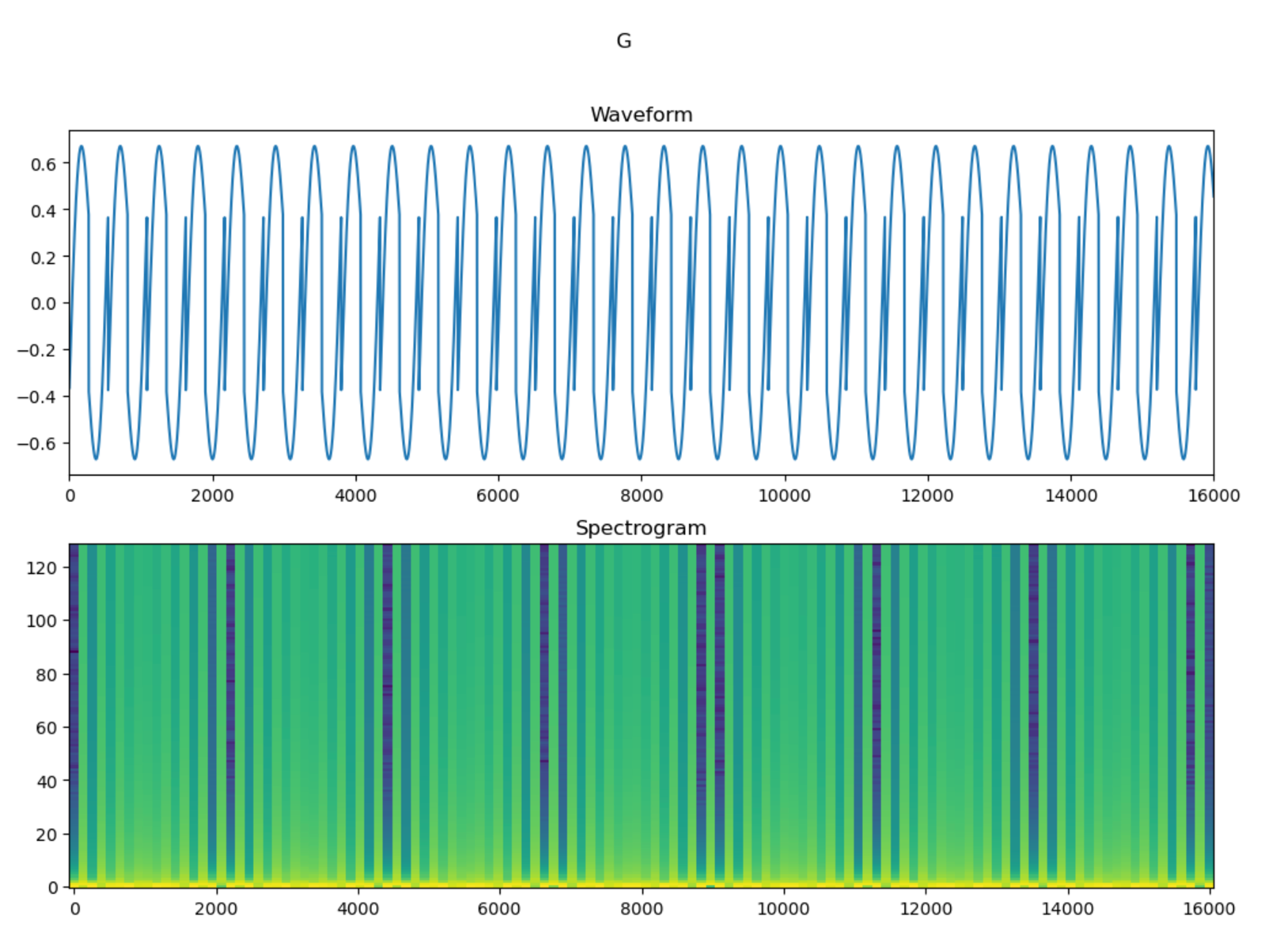
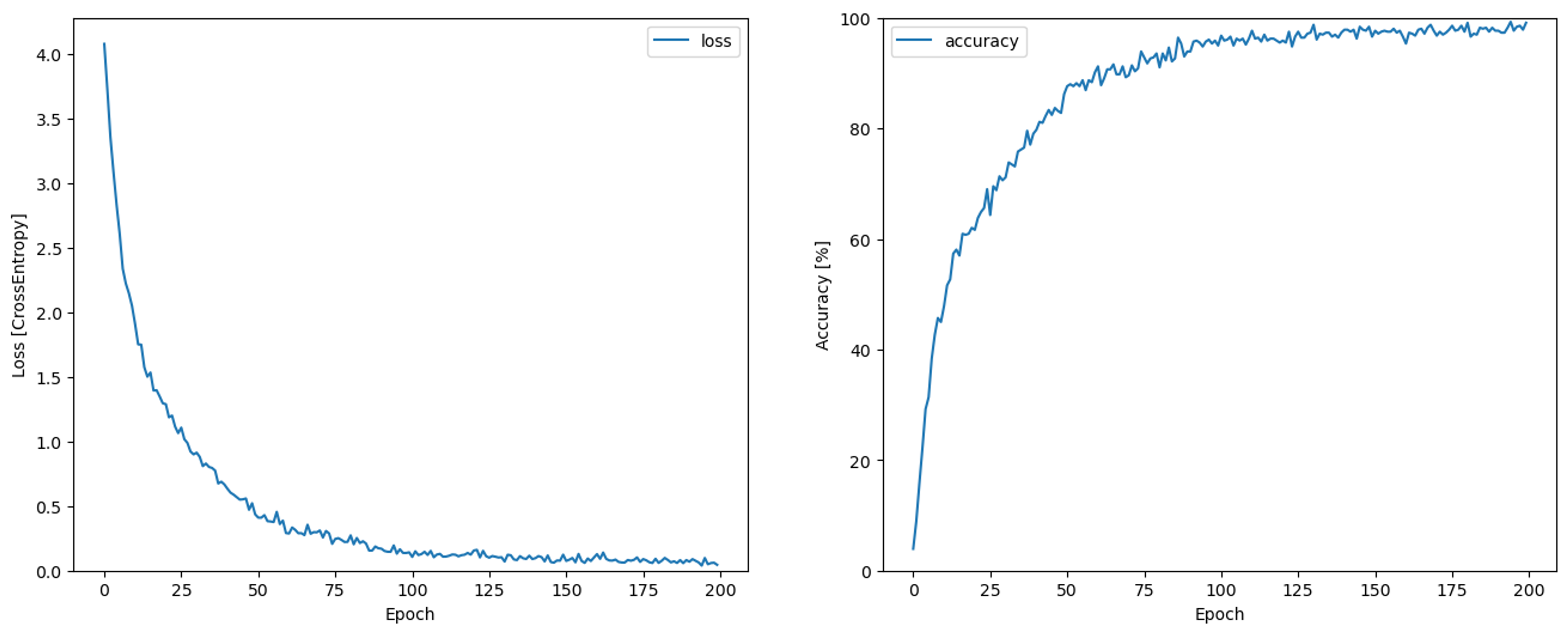
The LSTM model was created by following a TensorFlow tutorial on audio recognition [9]. Using a supervised learning approach, each frequency from the encoded dataset was exported as a WAV file and placed in a folder labeled with the respective decoded character. During model training, WAV files are converted to spectrograms, which the model uses for predicting text labels associated with audio characteristics (Figures 4 and 5). The model was intentionally overfit for testing purposes and not intended to generalize beyond the test set (Figure 6).
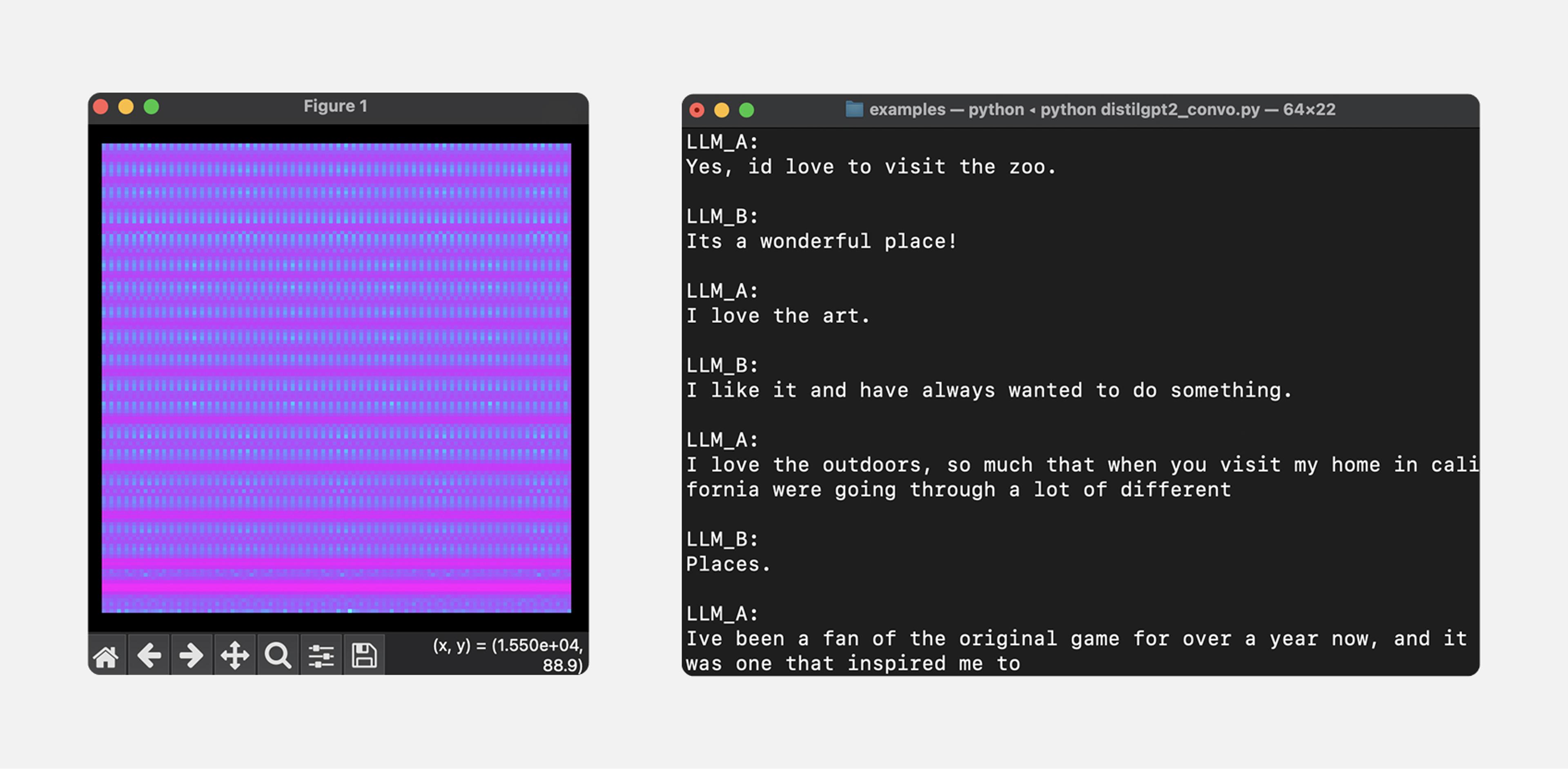
The simulated conversation is initiated by running a Python script in a terminal window on a PC. During the simulation, each character of an LLM response is encoded as an audio frequency, exported as a WAV file, and fed to the LSTM for inference. As the model makes predictions, spectrograms for each predicted character are visible on screen. Finally, audio of the predicted response is generated using Python Synthesizer [7].
The DistilGPT2 model used for this simulation was only trained well enough to be usable for demonstration purposes, but additional hyperparameter adjustments during training might produce less absurd conversations. An example simulation is shown in Figure 7 below and a demo video is available here.
Training LLMs on an Encoded Dataset
NanoGPT and DistilGPT2 models were also tested for their ability to generate responses after being trained on a fully encoded subset of the Open Assistant Conversation Dataset (oasst2) [4]. The dataset is structured such that rows alternate between prompts and responses, where every even row (and index 0) is a prompt, and every odd row is a response.
To encode the oasst2 dataset, each character of a word is encoded using the character mapping and then reformatted. Since the full oasst2 dataset includes 161,443 prompt or response messages in 35 languages, but the original character mapping only includes English characters, only the English subset of the oasst2 dataset was used for model training. The final encoded dataset includes 61,278 rows for model training and 3,235 rows for validation.
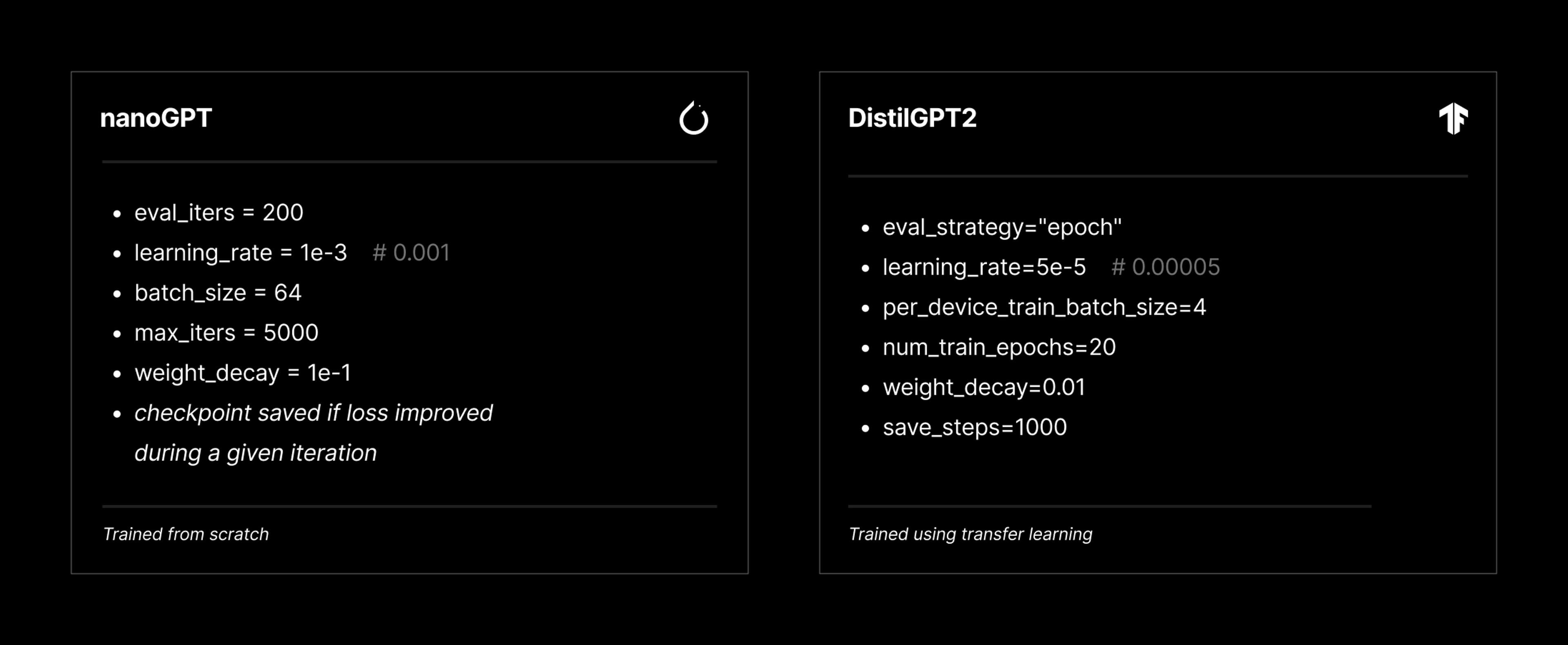
Most of the hyperparameters used to train nanoGPT were the defaults provided in the original repository. DistilGPT2 offers different hyperparameter options, but a comparable selection of hyperparameters is shown in Figure 8 below for both models.
Training results
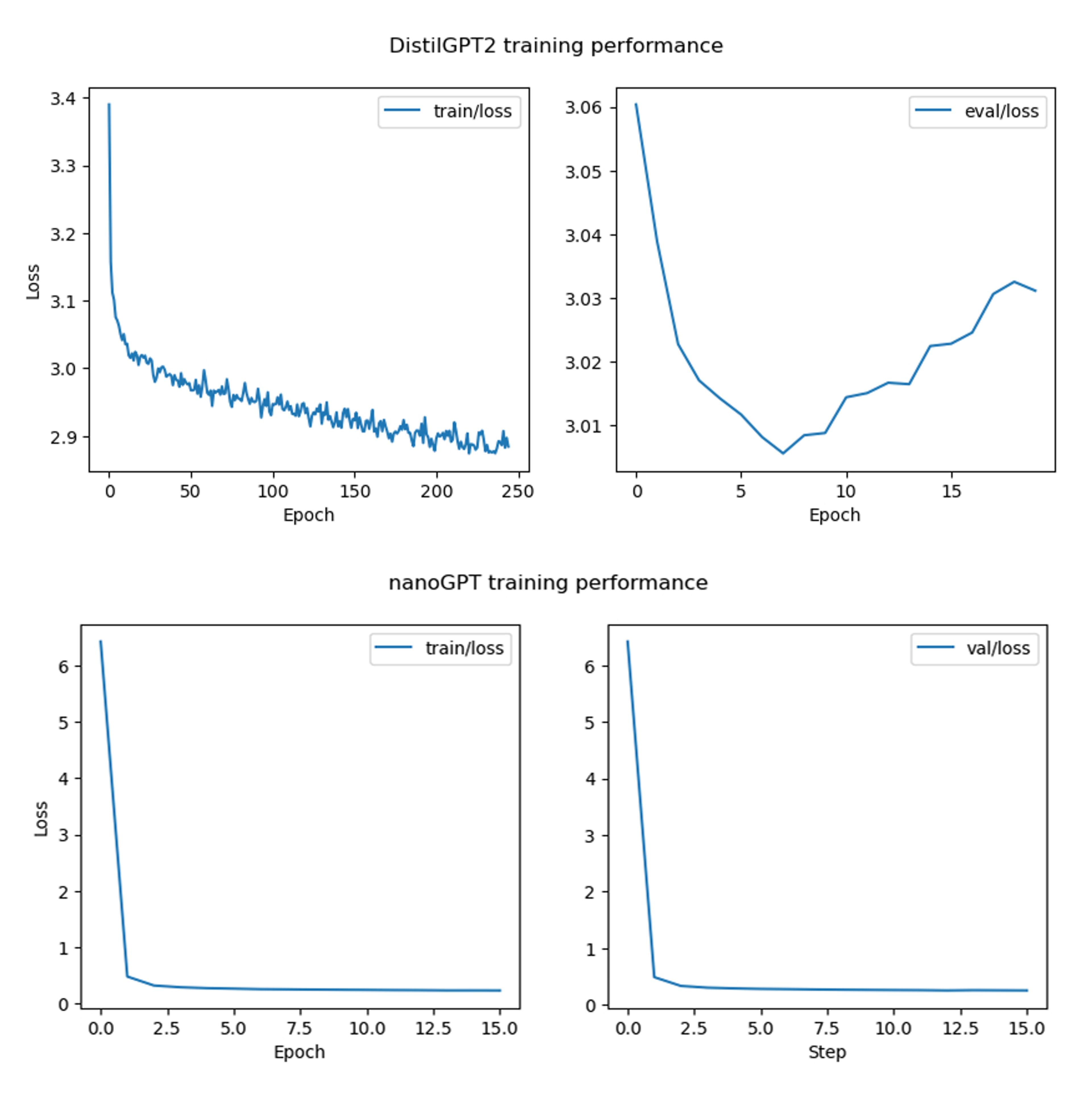
The nanoGPT model required ~2 hours and 43 minutes to complete training. Training and validation loss were nearly identical for each step. Loss improved rapidly at the beginning of training then remained flat, offering preliminary evidence that learning occurred.
The DistilGPT2 model took ~1 hour to train. Like nanoGPT, loss improved throughout training, but validation loss began to worsen by epoch 8 and continued deteriorating throughout the remaining epochs. Plots of the training results for both models are shown in Figure 9 below.
Model Testing
A selection of ten prompts from the validation set were used to test model performance (Figure 10). The plain-text prompts are encoded, tokenized, and provided to the trained model. Model responses are then cleaned, formatted, translated, and evaluated.
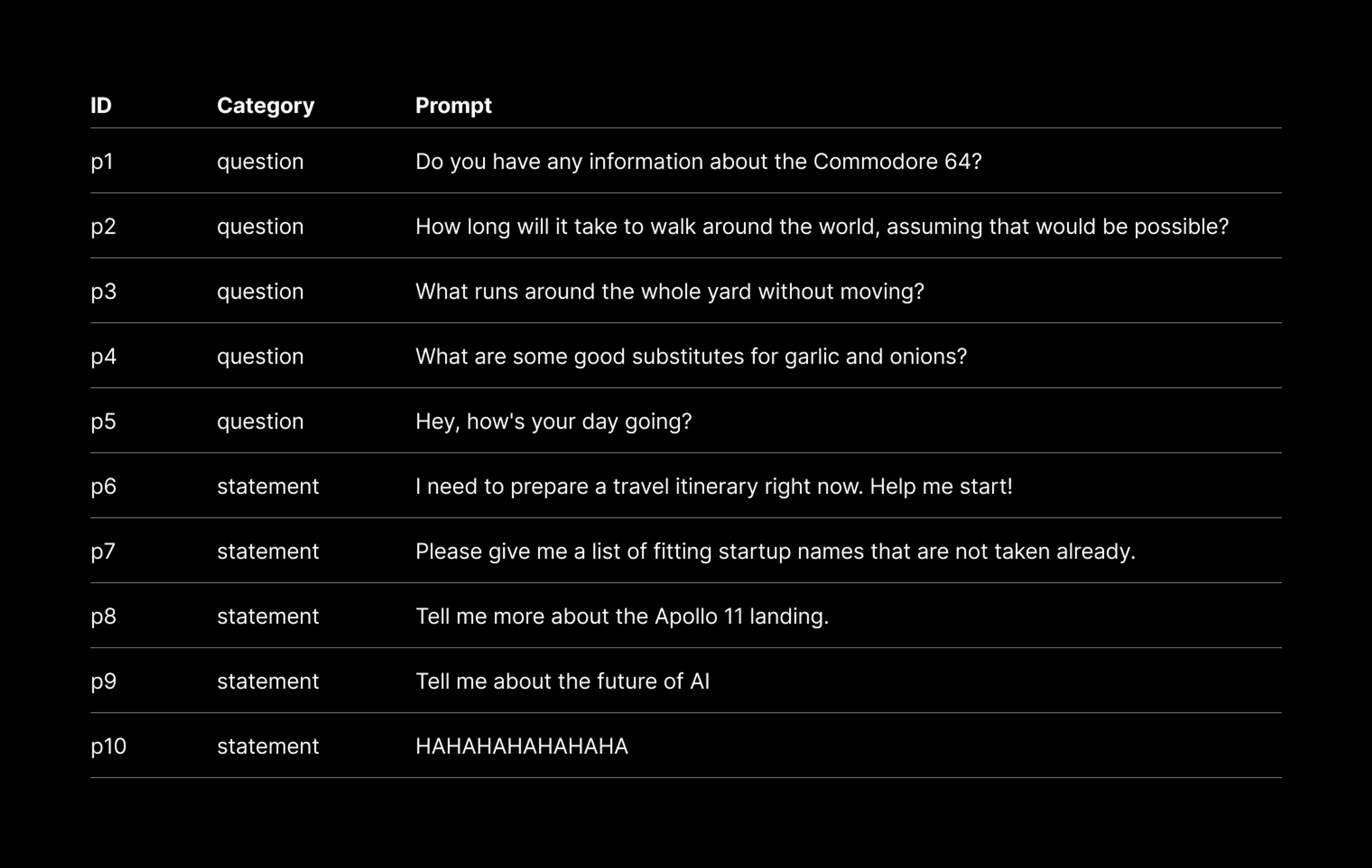
The responses from DistilGPT2 after training on an encoded dataset do not resemble anything that could be considered language. Surprisingly, the nanoGPT model appeared to learn patterns from the encoded dataset and was able to generate coherent responses.
Both models struggled to format responses properly, requiring substantial data cleaning and processing. Hallucinated patterns or incomplete number sequences appear in many responses. It is likely that additional hyperparameter adjustments will improve the performance of LLMs trained to generate encoded text that can be used for sonification. Figures 11 and 12 show the responses for each model.


Hybrid ensemble pipeline for LLM sonification using streamed audio
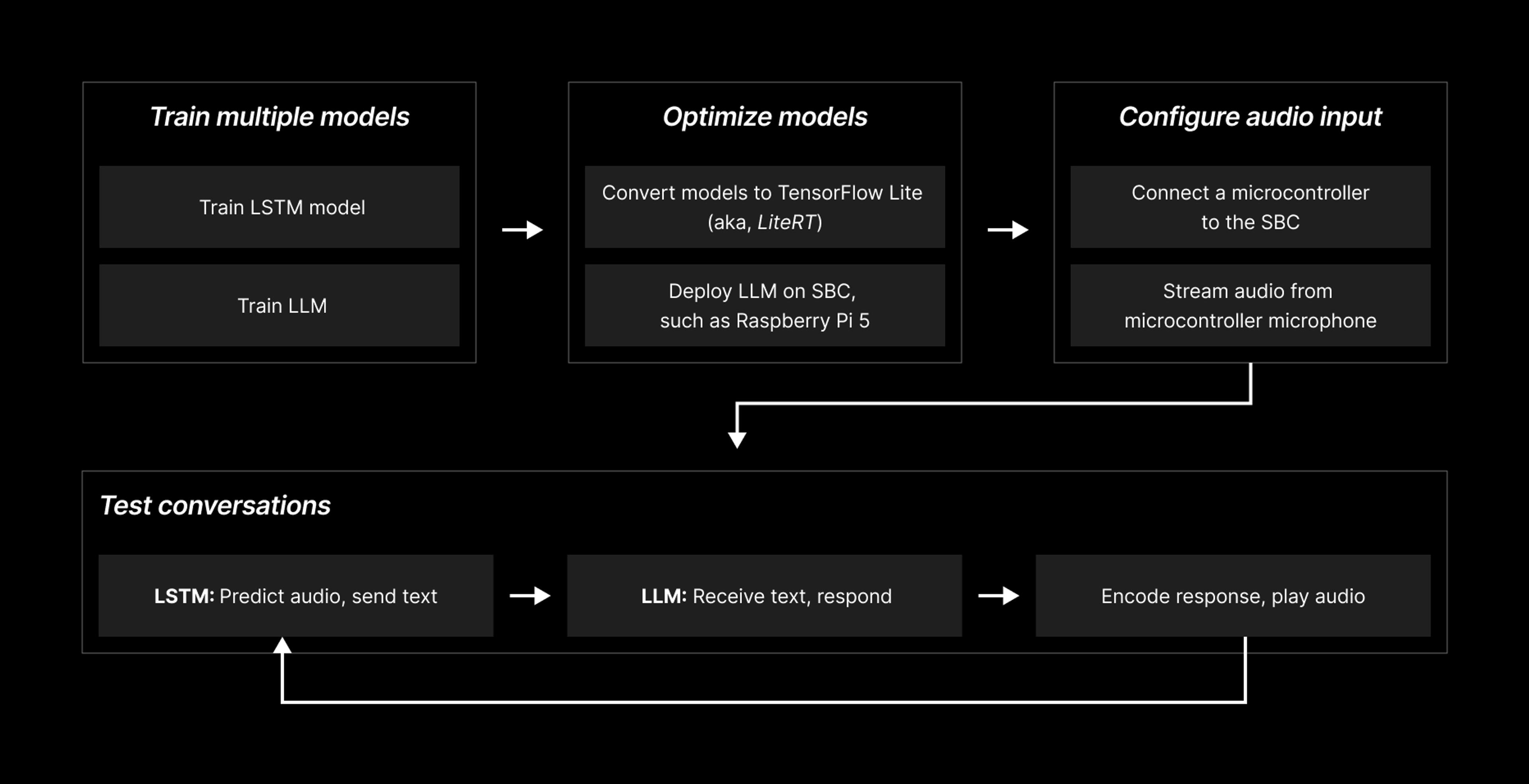
A second iteration of the simulated conversation was designed to use the LSTM model for predicting characters from a microphone input, rather than generating predictions from WAV files. It is assumed that such an adjustment could make LSTM suitable for inclusion in a hybrid ensemble by reducing the latency between encoded exchanges with LLMs. An example of such a pipeline is shown in Figure 13 above.
To test this idea, a Seeed Studio XIAO ESP32S3 Sense microcontroller (MCU) fitted with a digital microphone was used to for capturing audio. The MCU captures samples at a rate of 16 kHz and streams data to the serial port of an attached PC every 0.1 seconds. The PC connects to the MCU using pySerial [10], decodes the incoming data, and stores the data as chunks (~1,600 samples) in a buffer to prevent blocking. Data from the buffer is then accessed iteratively, converted to a tensor, reshaped, and used to create a spectrogram for model inference.
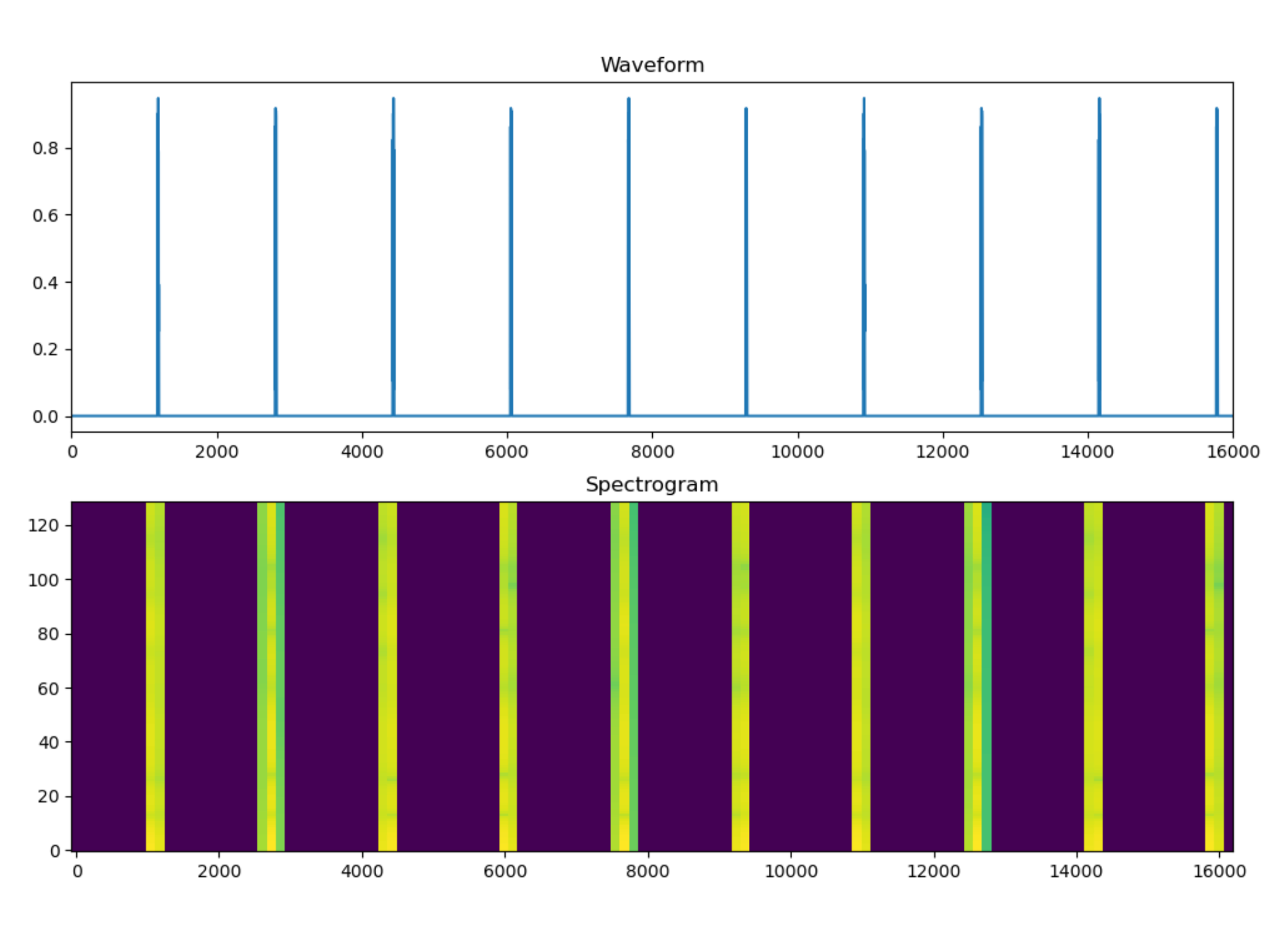
The LSTM model is highly accurate at predicting character strings from WAV files exported directly from the software synthesizer, but requires perfectly formatted data when invoked for live audio. Additionally, the sample rate necessary for capturing streaming audio exceeds the speed at which the model could be invoked on the hardware used for testing. Nonetheless, an initial test using the MCU indicates that the LSTM model can predict text from live audio using spectrograms in the same way it predicts text from WAV files (Figure 14). Further refinements to the full LLM sonification pipeline are needed before additional testing can occur, which were beyond the scope of work completed for this project.
Limitations
It is no secret that LLMs are challenging to train. Even the worst- performing models evaluated here required several hours of training time at 100% GPU utilization on a dedicated server. Training multiple LLMs for optimizing hyperparameter configurations was not feasible in the time available for this project, but should be explored in future work. Additionally, these models use different architectures and were trained using hyperparameter configurations that may not be comparable. As such, the evaluations here may not fully capture potential model performance on these tasks. For example, DistilGPT2 was trained using a transfer learning approach and likely retained patterns learned from previous training data. This may explain why it failed to learn and use new patterns from the encoded dataset. In contrast, nanoGPT likely performed well because it was trained from scratch and retained only patterns from the new training data. Future work should strive evaluate models based on their performance across equivalent hyperparameter configurations to form more accurate comparisons.
The subset of the oasst2 dataset used for training contained numerous mislabeled prompts and responses, including text in languages other than English. A more focused and refined dataset might improve the results observed in small-scale experiments like those described in this work.
Since AI models, including LLMs, will almost certainly see increased deployment on embedded systems and other devices with limited processing power, a secondary goal of this project was to simulate LLM conversations using a Raspberry Pi 5. However, a TensorFlow Lite conversion of the DistilGPT2 model was too large (~120M parameters) to be performant on a Raspberry Pi 5, requiring ~14 seconds to generate a single response. Given the model size and signal processing challenges encountered during testing, the encoded audio-to-text pipeline in this work remains incomplete. As such, it was not possible to evaluate the impact of sonification for enhancing explainability of LLM outputs with human subjects in this scope of work. In the future, researchers should continue exploring the ways in which sonification impacts human understanding of LLM outputs, including radically optimized models for enhancing AI explainability on embedded systems.
Conclusion
Despite the challenges experienced when attempting to use LLMs to generate data that can be used for sonification, nanoGPT was successfully trained on an encoded dataset and capable of generating encoded responses that could be translated into sentences. Additionally, sequences of audio like those produced in the simulated conversations described here might be useful aids for explaining natural language processing (NLP) and how LLMs generate responses. Researchers should continue experimenting with sonification as a means for enhancing explainability of LLMs, and seek to identify sonification techniques that compliment, rather than obfuscate, LLM outputs.
References
- Julia Amann, Alessandro Blasimme, Effy Vayena, Dietmar Frey, Vince I. Madai, and the Precise4Q consortium. 2020. Explainability for artificial intelligence in healthcare: a multidisciplinary perspective. BMC Medical Informatics and Decision Making 20, 1 (November 2020), 310. https://doi.org/10.1186/s12911-020-01332-6
- Thomas Hermann, Andy Hunt, and John G. Neuhoff (Eds.). 2011. The sonification handbook. Logos Verlag, Berlin.
- Hugging Face. 2024. distilgpt2. Retrieved May 1, 2025 from https://huggingface.co/distilbert/distilgpt2
- Hugging Face. 2025. OpenAssistant. Retrieved May 1, 2025 from https://huggingface.co/datasets/OpenAssistant/oasst2
- Andrej Karpathy. 2025. nanoGPT. Retrieved May 1, 2025 from https://github.com/karpathy/nanoGPT
- Colleen McClain, Brian Kennedy, Jeffrey Gottfried, and Monica Anderson. 2025. How the U.S. Public and AI Experts View Artificial Intelligence. Retrieved from https://www.pewresearch.org/internet/2025/04/03/how-the-us-public-and-ai-experts-view-artificial-intelligence/
- Yuma Mihira. 2025. Python synthesizer. Retrieved May 1, 2025 from https://github.com/yuma-m/synthesizer
- Björn W. Schuller, Tuomas Virtanen, Maria Riveiro, Georgios Rizos, Jing Han, Annamaria Mesaros, and Konstantinos Drossos. 2021. Towards Sonification in Multimodal and User-friendlyExplainable Artificial Intelligence. In Proceedings of the 2021 International Conference on Multimodal Interaction, October 18, 2021. ACM, Montréal QC Canada, 788– 792. https://doi.org/10.1145/3462244.3479879
- Simple audio recognition: Recognizing keywords | TensorFlow Core. TensorFlow. Retrieved May 1, 2025 from https://www.tensorflow.org/tutorials/audio/simple_audio
- pySerial — pySerial 3.4 documentation. Retrieved May 1, 2025 from https://pyserial.readthedocs.io/en/latest/pyserial.html

