AI-Generated Image Detection

The work below was conducted as part of a semester-long project for the Feature Engineering (CSCE 5222) course at the University of North Texas during the Summer 2025 semester. The descriptions included here were written for a term paper summarizing the results of this project, which can be downloaded here. The code is available on GitHub here.
I. Introduction
The image generation capabilities of artificial intelligence (AI) models are becoming increasingly more sophisticated. Consequently, humans may soon be unable to visually distinguish between images made by people and images generated with AI. This issue has practical implications for preventing the spread of misinformation, modernizing copyright laws, and cybersecurity [1]–[4]. The work presented here compares deep learning and feature-engineering approaches for binary classification of real or AI-generated images.
II. Background
Modern generative AI tools frequently rely on diffusion models for image generation, producing significantly higher quality images than previous generations of models reliant on generative adversarial networks (GANs) [2]. Diffusion models learn to generate images by deconstructing sample data, adding noise, then reversing the process [5]. AI-generated images are typically produced using either text-to-image (i.e., from a text prompt) or image-to-image (i.e., from an example image) techniques [2].
Existing AI-generated image detectors often compute statistical differences between real and AI-generated images to identify features that can be used in a binary classification task [4]. Noise and visual artifacts within the frequency domain are often discriminating features that numerous classifiers attempt to detect [1], [6]. Several studies describing these techniques also produced datasets that can be used for training novel classifiers. CIFAKE [7] is one such dataset, which consists of 60,000 AI-generate images and 60,000 real images from the CIFAR-10 dataset [8].
Given the rapid advances in image generation capabilities, models trained on older examples of AI-generated images struggle to generalize to images generated by newer generative AI models. For example, since CIFAKE was created using Stable Diffusion v1.4 and the latest Stable Diffusion version at present is v3.5, CIFAKE is likely ill-suited for training models to classify modern AI-generated imagery. While numerous computational methods for detecting AI-generated imagery exist, an optimal approach for this task has not yet been identified [1], [2].
The work presented here explores novel methods for detecting AI-generated images by comparing deep learning and feature-engineering approaches for binary classification. It seeks to answer the question: How effective is a feature engineering approach for AI-generated image detection compared to a deep-learning approach? Given the techniques describe in the extant literature, it is expected that a feature engineering approach will detect AI-generated imagery faster and more accurately than a deep learning approach.
III. Methodology
A. Ethical framework
This work applies a rights-based ethical framework. It is asserted that the proliferation of AI-generated imagery online has the potential to elicit human reactions that can result in violations of natural and legal rights. Individuals should be able to decide if they wish to view AI-generated images by employing tools that identify and filter out AI-generated images if they so choose.
Since detecting AI-generated imagery remains an unsolved problem, exposure to AI-generated images online is nearly unavoidable. For example, reports of deceptive AI-generated imagery impacting the stock market highlight the macro-level effects of this issue [9]. However, these technologies have not existed long enough to evaluate the impact AI-generated images may have at an individual or developmental level.
While AI-image detection tools are urgently needed, they could be misused just as easily as AI-generated content itself. It can be argued that generative AI has broadened access to high-quality visual design and photography assets, helping to democratize a skill that historically required training and experience. The use of AI-generated content could constitute a form of free speech or expression such that deploying AI image detectors might be used as a form of censorship. AI image detection tools may also be prone to misclassification, which could provoke unwarranted scrutiny for journalists or individuals who create original artwork.
Despite the potential for AI-image detection tools to be misused, the development of these tools is important for hedging against both the known and unknown risks of photorealistic imagery that is indistinguishable from reality.
B. Dataset

Using a collection of photographs from the Unsplash random images collection [10], four AI models were prompted to generate photorealistic replications of the images. The final dataset includes 40 real photos and 40 AI-generated replications that better represent the capabilities of modern generative AI tools. Examples of real images and their AI-generated counterparts are shown in Figure 1. The AI tools used to create images for this project are listed in Table 1.

C. Feature extraction
Noise, color, and keypoint details for both real and AI-generated images were statistically analyzed to establish a pairwise comparison of image features. Feature importance was determined by identifying the features with the greatest differences between groups.
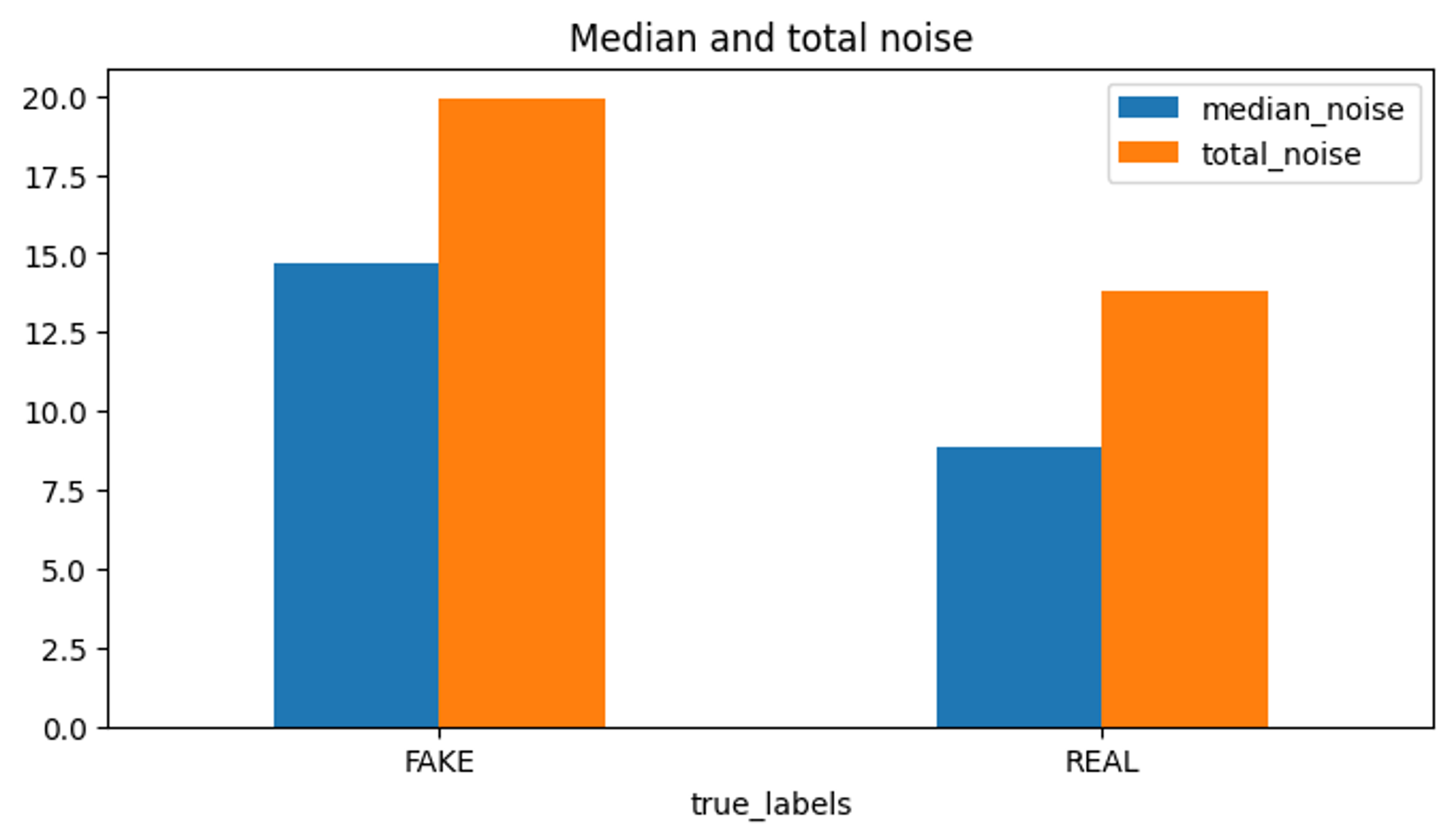
The standard deviations of total image noise and noise from individual RGB color channels were estimated using the estimate sigma method from scikit-image [11]. AI-generated images exhibit ∼44% more noise overall than real images, with a mean noise value ∼66% higher than real images. A comparison of mean and total noise for both groups is shown in Figure 2.
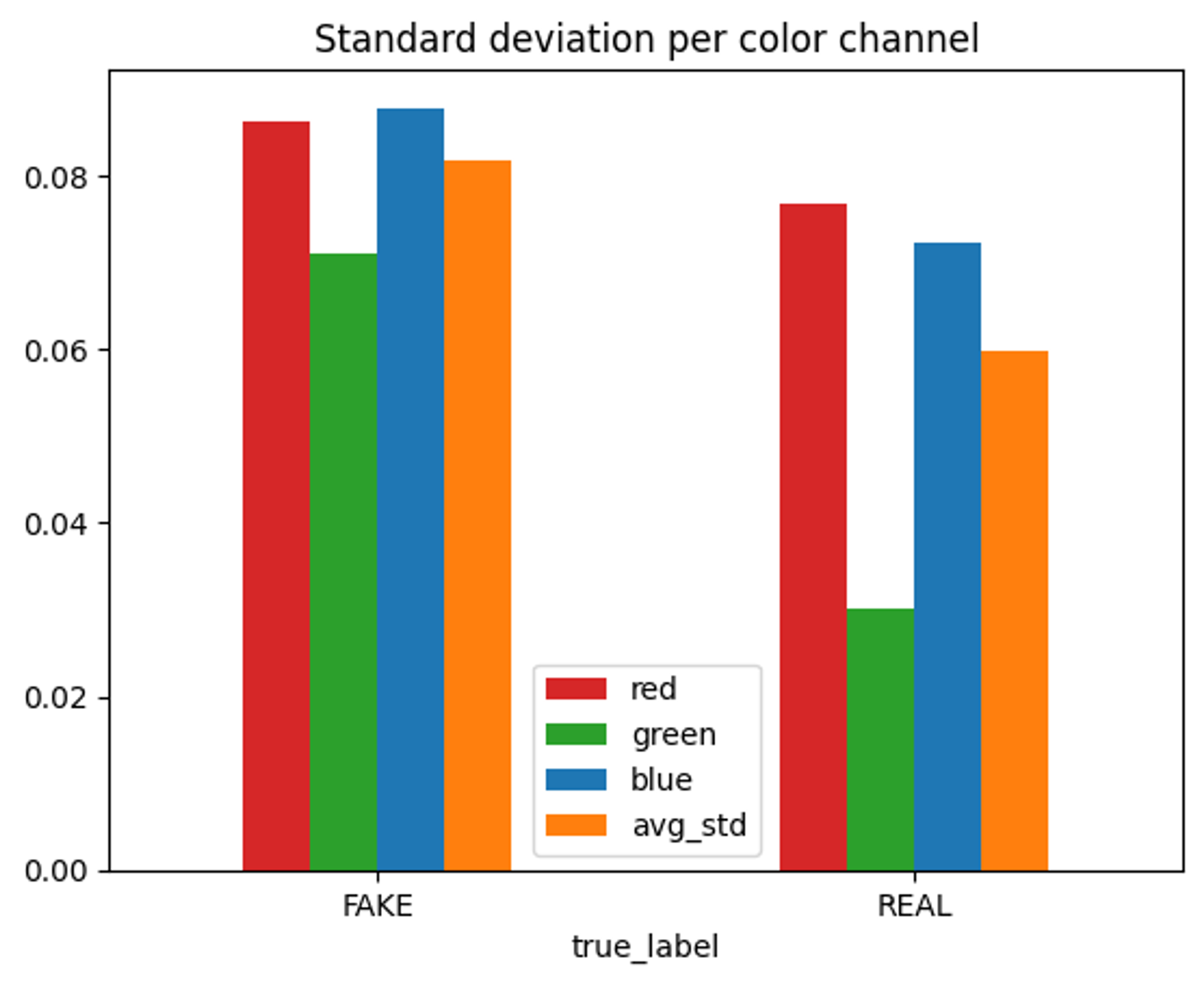
AI-generated images show a higher standard deviation of colors in each channel compared to real photographs (Figure 3). The green channel shows the lowest standard deviation for both fake and real images, but is also the channel with the greatest difference in standard deviation between the two categories.
The greatest difference in keypoint features between AI-generated images and photographs exists between the mean values. However, keypoint features exhibit less overall variation than noise or color features, and are excluded from the final model.
D. Model training
Images were resized to 128×128 pixels for both models during preprocessing and a train test split of 80% train images and 20% test images was applied. Training the feature-engineered model involved extracting the RGB values from all images, calculating noise and color variance, combining the statistics, and normalizing the results. The normalized data was then used to train a Multilayer Perceptron (MLP) model for binary classification. The deep learning model is a Convolutional Neural Network (CNN) modified from a TensorFlow tutorial on image classification [12]. Trained models output a value between 0 and 1, which corresponds with the associated class name (i.e., REAL or FAKE). A value closer to 0 is more likely to be a real photograph, whereas a value closer to 1 is more likely to be AI-generated.
IV. Model Training Results
Both models were trained for 100 epochs with early stopping. The deep learning model achieved the best performance at epoch 50 with perfect validation accuracy and AUC scores of 1.0 (Figure 4). The feature-engineered model achieved the best results at the final epoch, with a validation accuracy of 0.75 and a AUC score of 0.6719 (Figure 6).
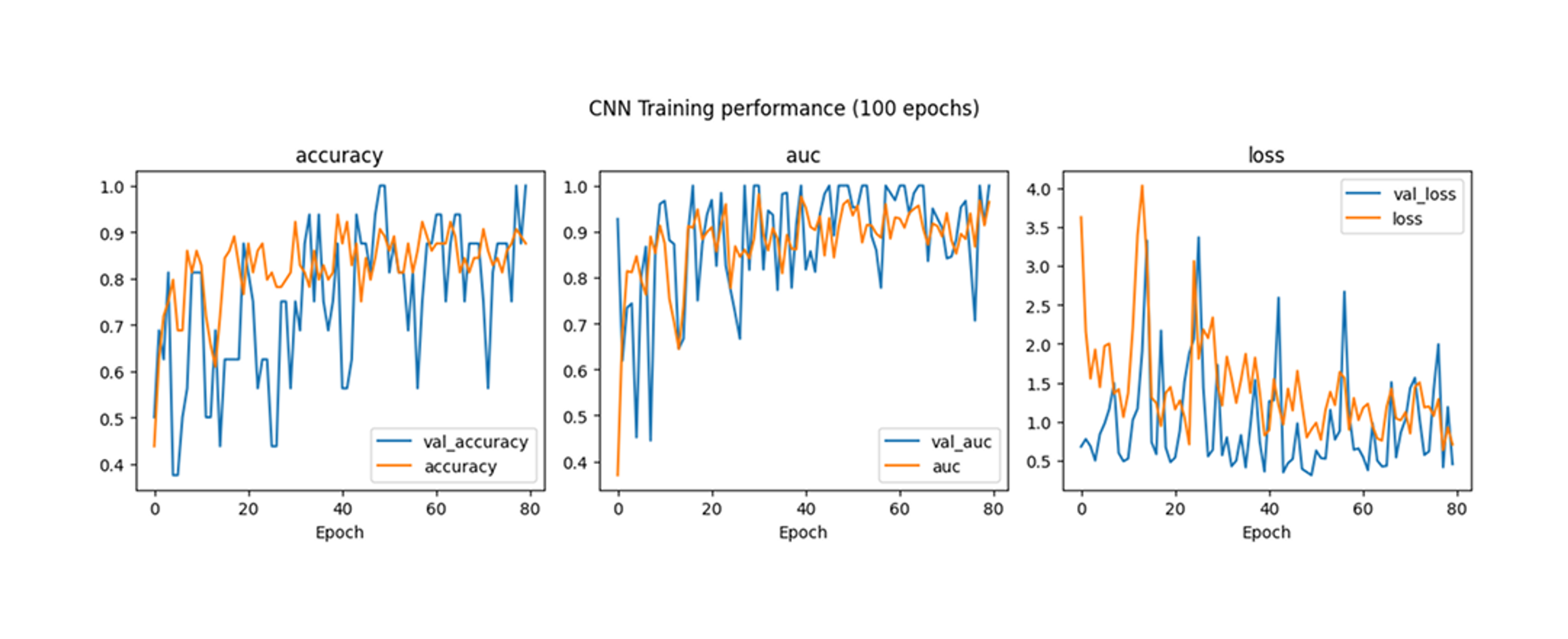
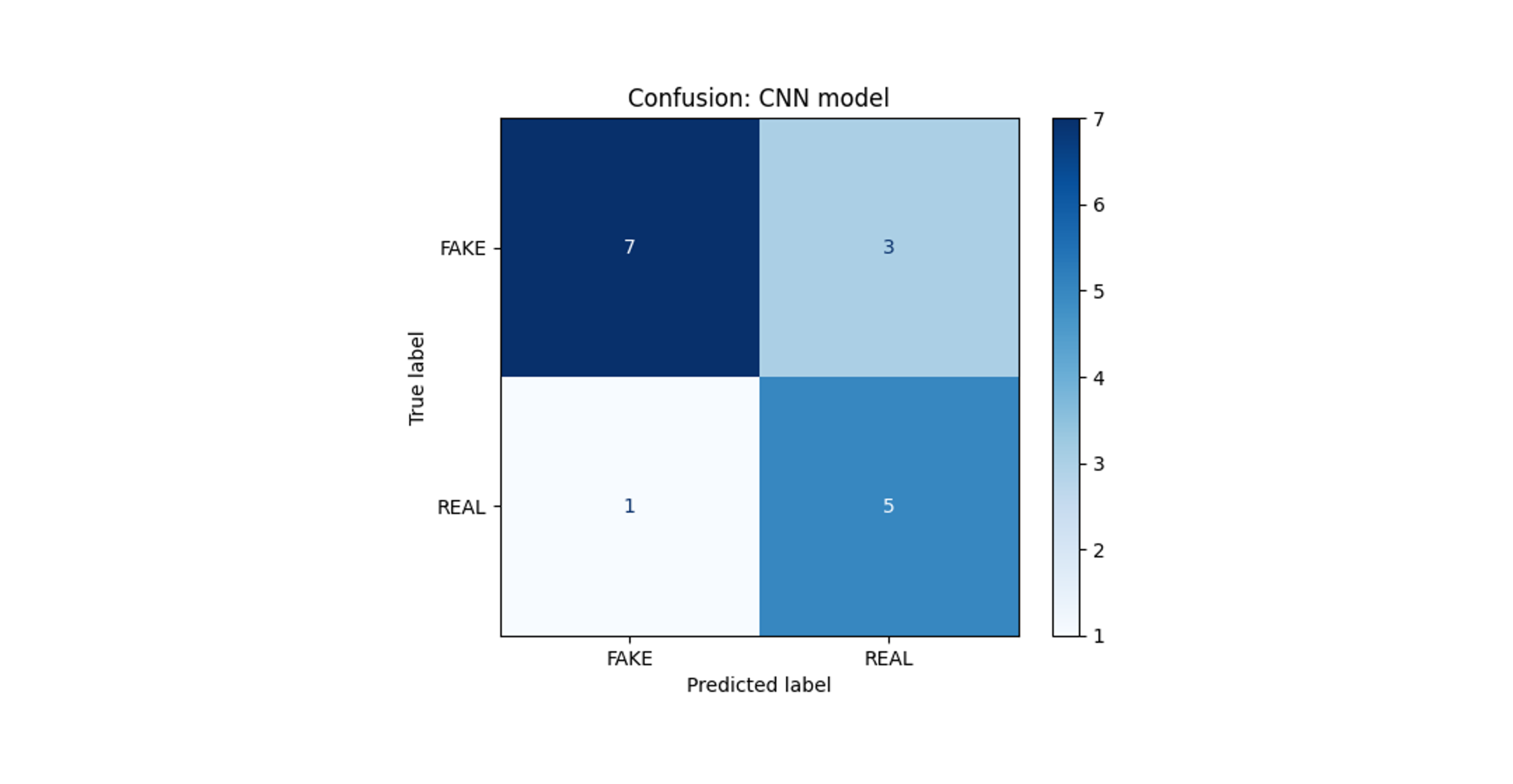
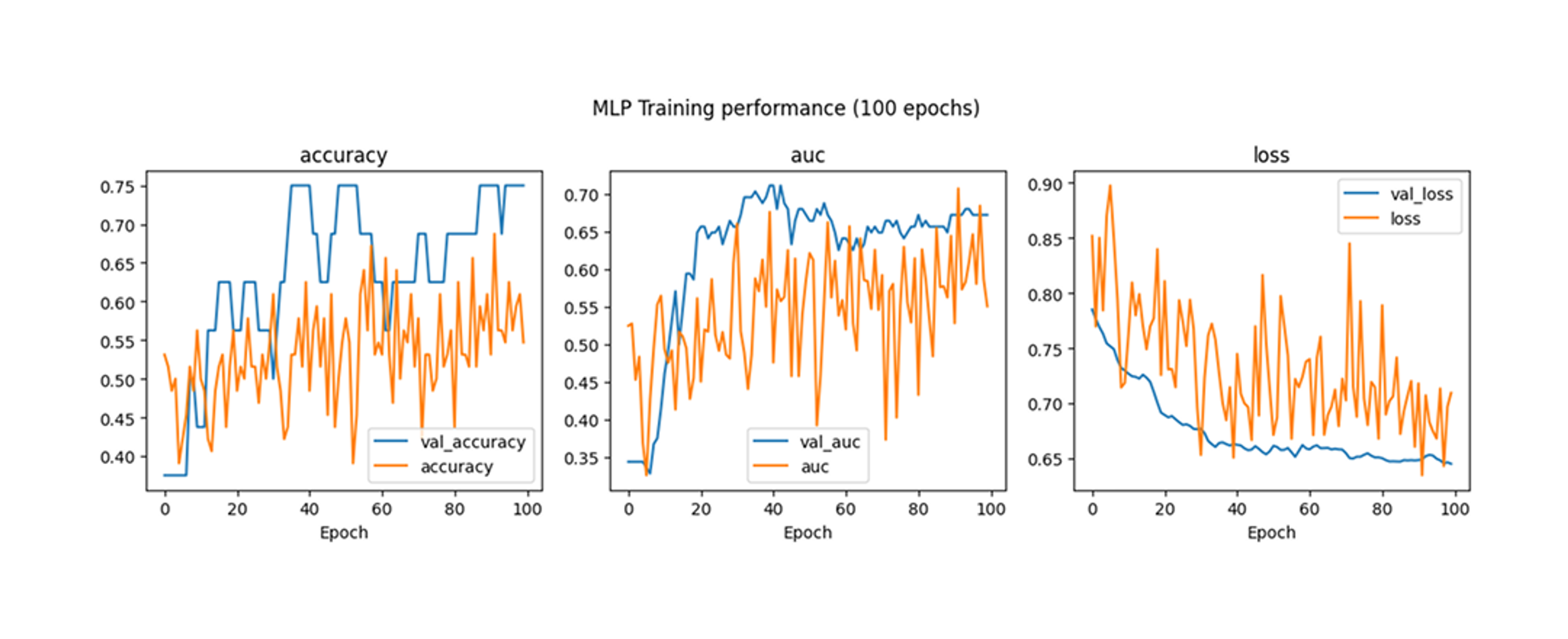
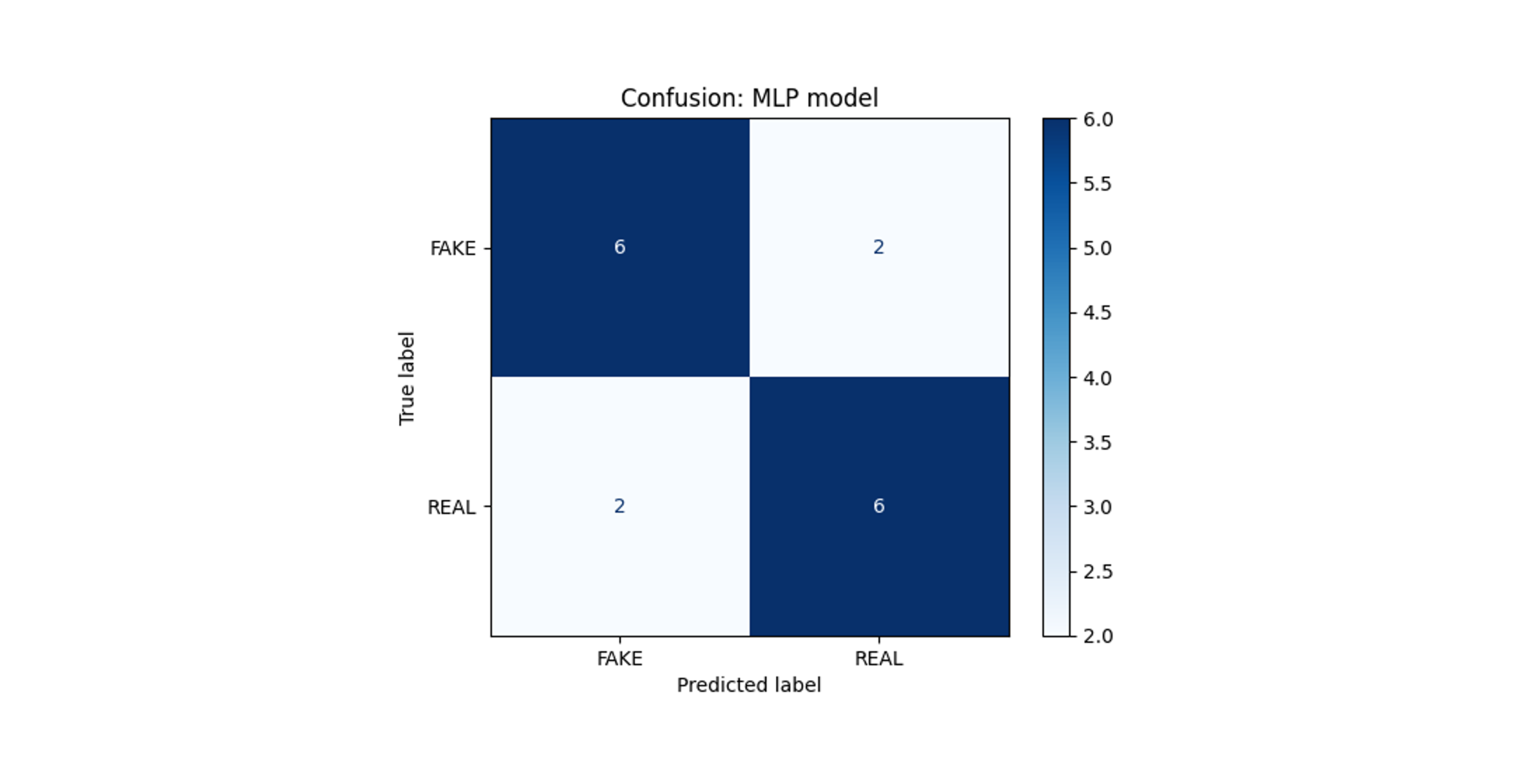
While both models were able to distinguish between photos and AI-generated images, the deep learning model outperformed the feature engineered model during training. It is likely that additional statistical features must be extracted to see improved results using the feature engineered model.
A. Implementation concept
Once training completed, a TensorFlow Lite version of each model was created and exported. The model can be loaded in the browser for testing using Tensorflow.js. A simple HTML interface for testing model predictions on images in a web browser was created by modifying an example found online [13], [14]. Once an image is loaded and the model generates a prediction, the predicted label and a confidence metric (i.e., probability) are displayed above the image (Figure 8).
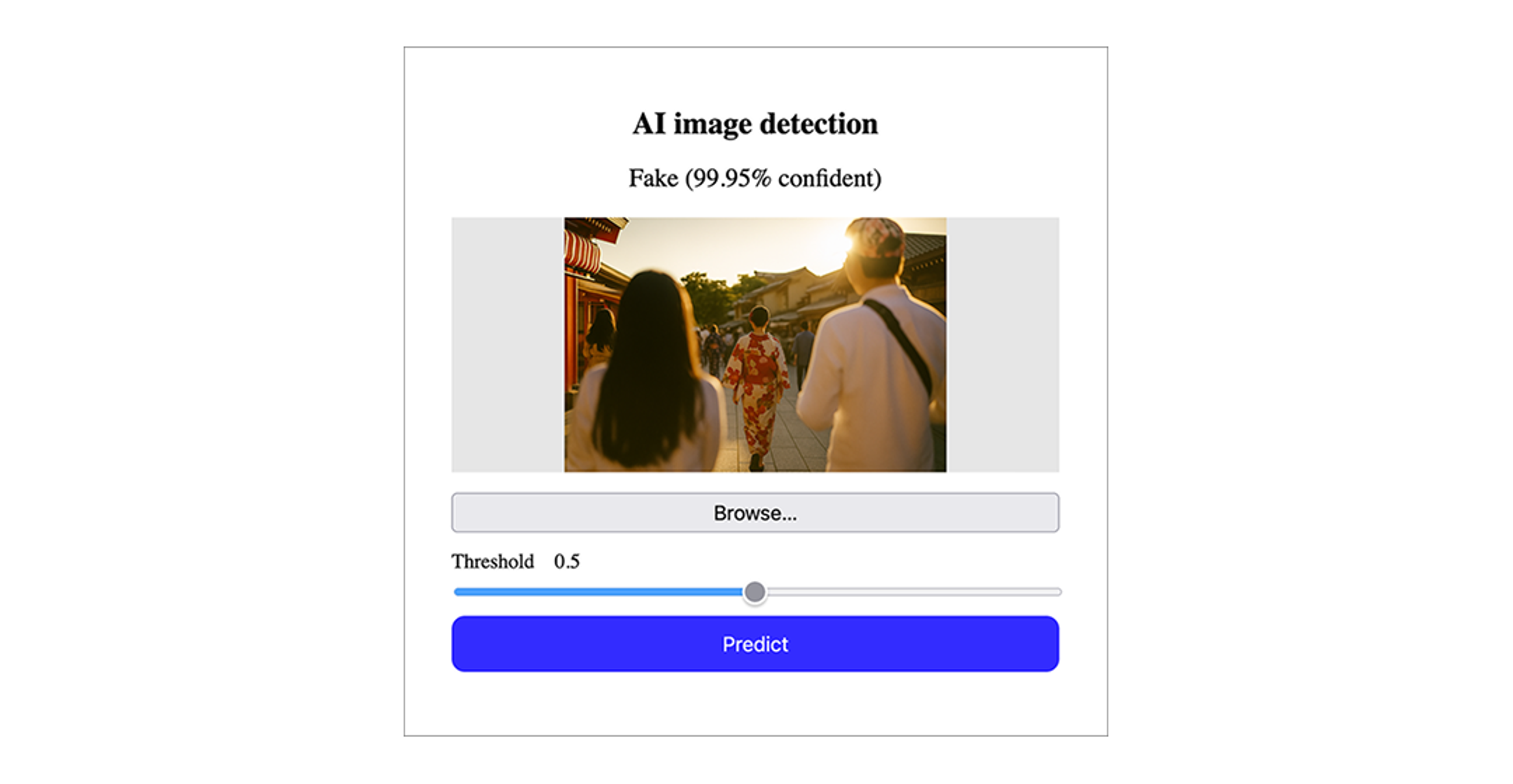
While this implementation concept is not a data visualization in the strictest sense, it does demonstrate how a data can be used to provide information about an image viewed online. More specifically, model outputs could be presented to end users in a way that indicates the likelihood that a given image is AI-generated. A threshold slider could also be added to change the minimum probability that an image is classified as fake, allowing users to calibrate the functionality of the tool.
V. Limitations and Future Work
A primary limitation of this work was the small size of the training dataset. Each AI-generated replication of a photograph was created manually, which is a time-consuming process. As such, it was infeasible to create a robust dataset with images featuring a variety of subject matter in the time available for this project. Additionally, the small dataset was split into training and validation sets, further limiting the amount of training data available to the models. The perfect training accuracy of the CNN model likely indicate that the model memorized this small dataset and its generalizability should be viewed with skepticism. Future work should strive to use much larger datasets with images featuring a variety of themes generated from multiple state-of-the-art generative AI tools.
Only two types of model architectures were tested in this work: a CNN and a MLP model. Existing research indicates a much wider selection of model architectures may be useful for AI-generated image detection. Future work should test multiple model types and compare the results of both deep learning and feature engineering approaches.
While the implementation concept demonstrates one possible way in which an AI-image detector might be used, it was not possible to explore additional implementation designs in the time available for this project. In the future, researchers should explore how to deploy these models in ways that end users might find beneficial.
VI. Conclusion
AI-generated image detection remains a challenging problem, but an effective technological solution has the potential for broad societal benefit. This work used modern AI tools to create a dataset of photographs and photorealistic AI-generated replications. The dataset was then used to compare the training results of both a deep learning model (CNN) and feature engineered model (MLP) for binary classification. Both models can distinguish between AI-generated images and photographs, but the CNN outperformed MLP model on the validation set. These results suggest that deep learning might be more effective approach for AI-generated image detection than a feature engineering approach, but additional work is needed to determine the generalizability of these findings.
References
- S. Yan, O. Li, J. Cai, et al., A Sanity Check for AIgenerated Image Detection, Feb. 2025. DOI: 10.48550/ arXiv.2406.19435. arXiv: 2406.19435 [cs]. (visited on 07/20/2025).
- D. Park, H. Na, and D. Choi, “Performance Comparison and Visualization of AI-Generated-Image Detection Methods,” IEEE Access, vol. 12, pp. 62609–62627, 2024, ISSN: 2169-3536. DOI: 10.1109/ACCESS.2024. 3394250. (visited on 07/20/2025).
- J. J. Bird and A. Lotfi, “CIFAKE: Image Classification and Explainable Identification of AI-Generated Synthetic Images,” IEEE Access, vol. 12, pp. 15642– 15650, 2024, ISSN: 2169-3536. DOI: 10.1109/ACCESS. 2024.3356122. (visited on 07/01/2025).
- X. Zhang, S. Karaman, and S.-F. Chang, “Detecting and Simulating Artifacts in GAN Fake Images,” in 2019 IEEE International Workshop on Information Forensics and Security (WIFS), Dec. 2019, pp. 1–6. DOI: 10.1109/ WIFS47025.2019.9035107. (visited on 07/20/2025).
- L. Yang, Z. Zhang, Y. Song, et al., Diffusion Models: A Comprehensive Survey of Methods and Applications, Dec. 2024. DOI: 10.48550/arXiv.2209.00796. arXiv: 2209.00796 [cs]. (visited on 07/20/2025).
- Z. Meng, B. Peng, J. Dong, and T. Tan, Artifact Feature Purification for Cross-domain Detection of AIgenerated Images, Mar. 2024. DOI: 10.48550/arXiv. 2403 . 11172. arXiv: 2403 . 11172 [cs]. (visited on 07/20/2025).
- CIFAKE: Real and AI-Generated Synthetic Images, https://www.kaggle.com/datasets/birdy654/cifakereal-and-ai-generated-synthetic-images. (visited on 07/01/2025).
- CIFAR-10 and CIFAR-100 datasets, https://www.cs.toronto.edu/˜kriz/cifar.html. (visited on 07/01/2025).
- FACT FOCUS: Fake image of Pentagon explosion briefly sends jitters through stock market, https://apnews.com/article/pentagonexplosion-misinformation-stock-market-ai-96f534c790872fde67012ee81b5ed6a4, May 2023. (visited on 07/20/2025).
- Unsplash random images collection, https://www.kaggle.com/datasets/lprdosmil/unsplashrandom-images-collection. (visited on 07/20/2025).
- Skimage.restoration.estimate sigma, https://scikit-image.org/docs/0.25.x/api/skimage.restoration.html#skimage.restoration.estimate_sigma
- Imageclassification—TensorFlowCore, https://www.tensorflow.org/tutorials/images/classification. (visited on 07/20/2025).
- N. Tiwari, NSTiwari/TFJS-TFLite-Object-Detection, Jun. 2025. (visited on 07/20/2025).
- N. Tiwari, [ML Story] Machine Learning on the browser: TF Lite meets TF.js, Nov. 2023. (visited on 07/20/2025).

